

Code Review Is the Bottleneck
Time to Rebuild It

Max Kanat-Alexander has spent two decades thinking about developer productivity at scale. He was the Technical Lead for Code Health at Google. He led LinkedIn's Developer Productivity and Happiness team. He wrote Code Simplicity. Now, as Executive Distinguished Engineer at Capital One, he shapes developer experience for 14,000+ technologists. When he talks about what slows engineering organizations down, it's worth paying attention.

At the AI Engineer Code Summit, he named the problem plainly: code review is a major bottleneck in the software development lifecycle. Not a minor friction point. Not something you solve with a passive-aggressive Slack reminder. A structural constraint that determines how fast your organization can ship. AI agents can generate code faster than ever; the review step has not kept pace. Waiting days for pull requests to bounce back for fixes means inefficiencies across every other step, eat whatever productivity gains faster code creation delivers.
The data backs him up. LinearB's 2025 benchmarks — analyzing 6.1 million PRs—put the average review time at 4 days and 7 hours. Google recommends one business day. Almost nobody hits that. 52% of developers report feeling "blocked and slow" due to inefficient reviews.
Meanwhile, creation speed is accelerating. DORA's 2025 report found that developers using AI coding assistants complete 21% more tasks and merge 98% more PRs. But organizational delivery metrics stay flat. Individual developers are producing more; organizations are not delivering more. The difference between the two statements lies in the review queue. More code created. Same throughput. The bottleneck moved from writing to reviewing, and we are pretending it didn't.
The 15% Problem
We treat code review as a bug-finding exercise. The research says otherwise.
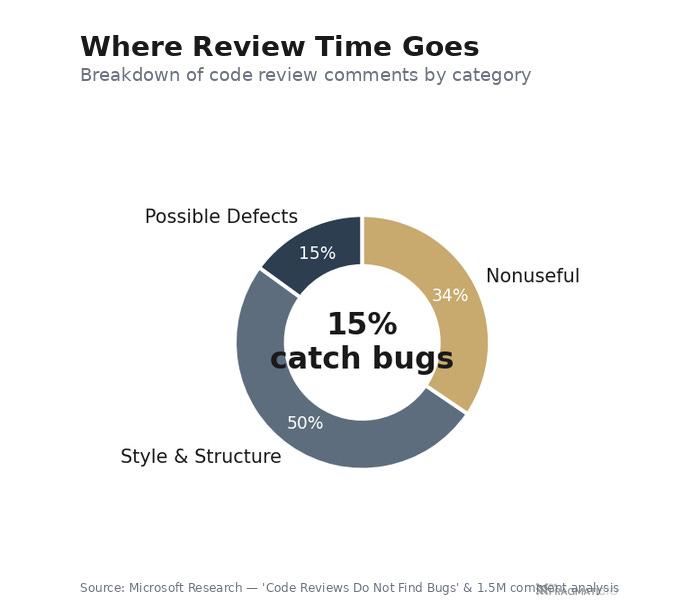
Microsoft Research published a paper with a title that should have changed the industry: "Code Reviews Do Not Find Bugs." Only 15% of review comments indicate a possible defect. The remaining 85% are about style, structure, and understanding. A separate Microsoft study analyzing 1.5 million review comments across five projects found the same pattern — most comments addressed structural issues and formatting, not functional bugs. And 34.5% of all review comments were classified as "nonuseful."
Google's own research confirms the mismatch. Sadowski et al.'s case study found that the primary drivers for code review at Google are education and maintenance of organizational standards. Bug prevention is third. Not first. Not second. Third. The majority of changes have one reviewer and no comments beyond authorization to commit. The company with the most-studied code review process in the industry does not treat review primarily as a bug-finding exercise.
Put the numbers side by side. Developers spend 5-6 hours per week reviewing code — roughly 12.5% of a 40-hour workweek. Only 15% of the time catches bugs. Most of the rest catch style issues that a linter could handle. We are spending an eighth of our engineering capacity on a process that, by the data, mostly does things machines can already do---while the things only humans can do (architecture validation, business logic review, design judgment) get compressed into whatever attention is left over.
Think about what this means for your engineering organization. Your senior developers---the ones with the architectural knowledge, the domain expertise, the judgment that takes years to develop---are spending a measurable chunk of their week catching formatting inconsistencies and style violations. These are the same people who need to review whether a microservice boundary makes sense or whether a database schema will scale. The process is not just slow. It is misallocated. And the misallocation has a compounding cost; every hour a senior engineer spends on style nits is an hour they are not spending on the judgment calls that prevent production incidents six months later.
How We Look at Code
Beyond what we focus on, there is a more fundamental problem: the way code changes are presented to reviewers is working against their cognition.
Open a pull request on GitHub. The files appear in alphabetical order. Not grouped by feature. Not organized by execution flow. Not sorted by business impact. Alphabetical.
A PR touching `auth-controller.rb`, `auth-service.rb`, `auth-test.rb`, and `migration-add-auth-table.rb` scatters those files across the diff. The reviewer has to mentally reconstruct that these four files represent a single autentication featurepiecing together intent from filenames that happened to land near each other in the alphabet. Multiply that by a PR with fiften or twenty files and the cognitive load becomes the bottleneck itself.
This is not a minor UX complaint. Research on file ordering strategies found that 57.6% of developers report alphabetical ordering increases context switching, disrupts logical reasoning, and contributes to review fatigue. 2025 research on review comprehension identifies the core challenge: code review requires loading someone else's mental model into your own working memory — its architectural choices, naming conventions, edge cases, and assumptions — in a shorter window than the original author had. Alphabetical file listing makes that reconstruction harder, not easier.
The SmartBear/Cisco study---the largest code review study ever conducted---found that defect detection rates plummet after 60-90 minutes of continuous review. The optimal window: under 400 lines of code at under 500 lines per hour. And 61% of the study's reviews found no defects. Reviewer fatigue and cognitive overload are likely factors; the way we present code to reviewers compounds both.
Cognitive load is not a soft concern. It is the mechanism by which review quality degrades. A reviewer who is mentally exhausted from context switching between unrelated files in a large PR is not going to catch the subtle architectural flaw in file seventeen. They are going to approve it and move on.
The problem is structural. How we look at code matters as much as what we look at.
Verification Debt
AI is not just failing to fix the review bottleneck. It is widening it.
Werner Vogels, AWS's VP and CTO, named the dynamic at re:Invent 2025: "You will write less code, 'cause generation is so fast, you will review more code because understanding it takes time. And when you write a code yourself, comprehension comes with the act of creation. When the machine writes it, you'll have to rebuild that comprehension during review. That's what's called verification debt."
Verification debt. The term is precise. When a developer writes code, comprehension is a byproduct of creation; you understand the code because you made the decisions that shaped it. When a machine writes code, that comprehension must be rebuilt from nothing during review. The reviewer pays the debt the machine deferred.
The data confirms this is measurable. Sonar surveyed 1,100+ enterprise developers and found that 96% don't fully trust AI output — yet only 48% always verify AI-generated code before committing. AI now accounts for 42% of all committed code, a number expected to reach 65% by 2027. And 38% say reviewing AI-generated code requires more effort than reviewing human-written code.
The quality gap is quantifiable. CodeRabbit's analysis found that AI-generated PRs contain roughly 10.83 issues each, versus 6.45 for human-written PRs — 1.7x more issues overall, with 1.4x more critical issues and 1.7x more major issues. This makes intuitive sense; when you write code yourself, you build a mental model as you go. When a machine writes it, that model doesn't transfer. The reviewer has to construct it from scratch, and the code itself offers fewer contextual clues about why it was written the way it was.
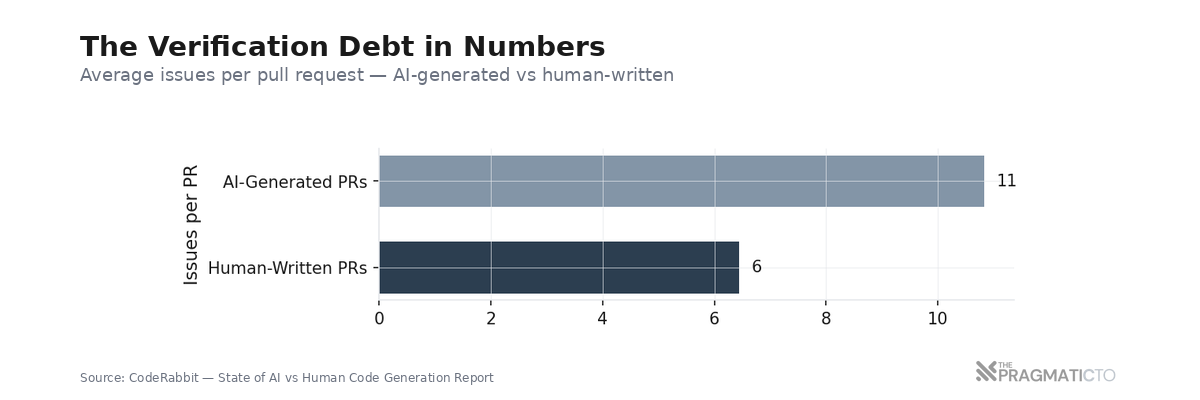
Now do the arithmetic. DORA 2025 reports that developers using AI interact with 47% more PRs daily. 1 in 7 PRs now involve AI agents, up from under 1% in 2022. More PRs per day. More issues per PR. Same number of human reviewers---or fewer, given the industry layoffs of the past two years. The math doesn't work. Something in the review process has to change, or the bottleneck doesn't just persist. It widens with every AI-generated commit.
Three Shifts
Code review needs a structural redesign. Not a better checklist. Not a faster LGTM. Not "just add an AI reviewer and call it done." Three simultaneous shifts in how we think about the review step.
Shift 1: Change how code is presented.
Stop showing reviewers files in alphabetical order. Organize changes by business impact, change type, or execution flow. Group related files together so the reviewer understands the intent of the change before reading individual diffs---what business capability is being added or modified, which files work together, how data flows through the system. Show how a request moves through the changed files: from routes to controllers to services to database migrations. The reviewer should see the story of the change, not an alphabetical list of filenames.
The file ordering research showed that 57.6% of developers experience increased context switching from alphabetical ordering. This is a structural problem with a structural solution; change the presentation, and you change the cognitive load.
Shift 2: Change what humans focus on.
Not all review work is equal. A layered model separates the mechanical from the judgment-dependent:
Layer 1 - Automated: Linters, static analysis, type checkers, AI reviewers. Style problems, obvious bugs, security vulnerabilities, performance issues, missing null checks, and common anti-patterns. This is roughly 80% of review issues — the work machines can handle now.
Layer 2 - Human review: Architectural decisions, business logic validation, design reviews, failure modes, domain-specific judgment, cross-system interactions. Does the code do what the busin’s needs? This is the 20% that requires human judgment.
Layer 3 - Knowledge sharing: Google found that the primary value of code review is education and maintaining standards. This layer transforms review from a bottleneck into a competitive advantage — but only when humans are freed from the mechanical work in Layer 1.

Google already operates this way. Stylistic concerns are pushed into automated lints; human review focuses on decisions that cannot be automated. The result: 97% developer satisfaction with their review process. That number is not a coincidence. When you stop asking humans to catch style violations, they have the cognitive bandwidth to catch architectural problems. The review becomes more valuable because it focuses on what humans are good at.
Shift 3: Change how work is structured for review.
Every study agrees on the sweet spot: 200-400 lines of code. PRs over 1,000 lines have a 70% lower defect-detection rate. Small PRs---under 200 lines---get approved 3x faster.
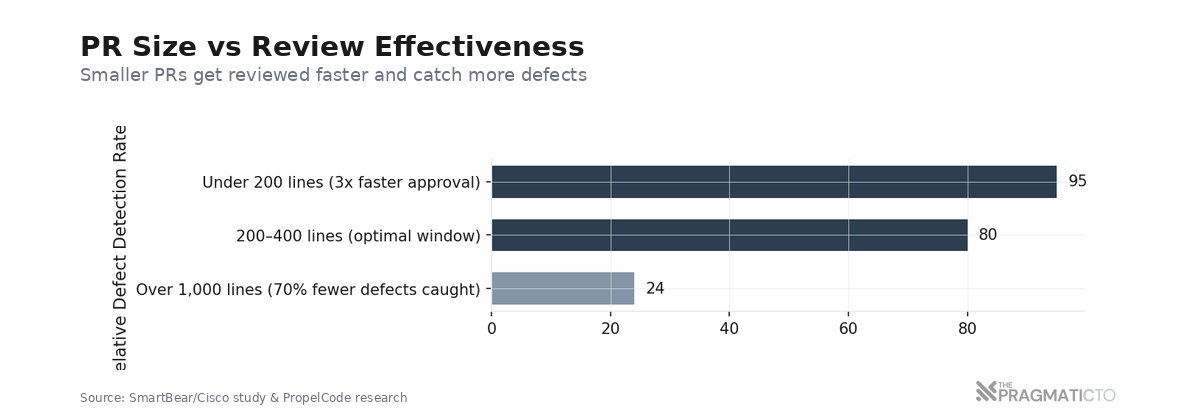
Stacked PRs make small batches practical. Stack small, dependent changes atop one another; each is reviewed and merged independently. Different reviewers can work on different layers simultaneously---a frontend lead reviews the UI diff while a domain expert reviews backend abstractions. The changes flow in parallel instead of waiting in a serial queue. Asana reports that engineers save up to seven hours per week on code reviews using this approach. Meta has used stacked diffs via Phabricator as a core workflow for years; the pattern is proven at scale.
Google proved this at scale. 90% of their reviews have fewer than ten files. Most changes are roughly 24 lines. Median review time: under four hours. Continuous review — small changes reviewed frequently rather than large batches reviewed at cycle end — reduces total lead time and prevents the bottleneck from reforming.
Three shifts. Change the presentation so reviewers understand the context before they read code. Shift the focus to what humans do better than machines. Change the batch size so reviews stay in the optimal cognitive window. None of these require revolutionary tooling; they require rethinking what the review step is for. You can adopt them independently — start with Shift 3 tomorrow without any tool changes, add Shift 2 as AI review tools mature, and invest in Shift 1 when you are ready to change how your team sees code.
The AI Reviewer Layer
AI code review tools are part of this equation — specifically, Layer 1 of the framework. They are not the whole answer, but they are a meaningful piece.
The landscape is maturing. 1 in 7 PRs now involve AI review agents. CodeRabbit has connected 2 million+ repositories and reviewed 13 million+ PRs. GitHub Copilot Code Review reached general availability in April 2025; over a million developers used it within the first month. Microsoft's internal AI reviewer now covers 90% of PRs — 600,000+ per month — with a 10-20% median improvement in PR completion time.
These tools handle the mechanical well: style inconsistencies, minor bugs, potential null references, security vulnerabilities, common anti-patterns. They catch the 80% of issues that don't require human judgment. They do not handle architectural decisions, business logic validation, or cross-system design. They cannot tell you whether a feature solves the right problem or whether an abstraction will hold under load. The distinction matters. AI reviewers are the automation layer that makes human review effective; they are not a replacement for human review.
The 10-20% improvement Microsoft reports is meaningful. It is not transformative. And it shouldn't surprise anyone---automating one layer of a three-layer problem produces incremental improvement, not structural change. The transformative gains come from combining AI review (Shift 2, Layer 1) with better code presentation (Shift 1) and smaller batches (Shift 3). No single change solves the bottleneck; the three shifts work together. Teams that adopt AI reviewers without changing PR size or code presentation will see modest improvements and wonder why the bottleneck persists.
Where This Breaks Down
This framework has limits. Every framework does. Acknowledging them matters more than pretending they don't exist.
Small teams. The layered model assumes enough people for differentiated review roles. A three-person startup can't separate AI and human review layers the way a fifty-person engineering org can; you don't have the headcount for specialized reviewers. For small teams, the framework simplifies: automate what you can, review what matters, keep PRs small. The principles hold; the implementation compresses.
Legacy codebases. Organizing PRs by business impact requires tooling that understands your codebase's structure. For legacy systems with tangled dependencies, business-impact grouping may not map cleanly. Shift 3 — small batches — is the highest-leverage change for legacy systems; start there.
Culture. Shifting from review-as-gatekeeping to review-as-knowledge-sharing requires more than tooling changes. Some teams have gatekeeping habits embedded in their identity; senior engineers derive status from being the bottleneck, and removing that bottleneck feels like removing their authority. The mechanical shifts (presentation and batch size) are easier to adopt than the focus shift. Start with what you can change mechanically and let the cultural shift follow. If you try to change the culture first, you will fail; change the process and the culture adapts.
Large changes. Some work — major refactors, database migrations, and cross-cutting infrastructure changes — resists the small-batch approach. You cannot meaningfully review a database migration in 200-line increments. For these, the cognitive load reduction from Shift 1 is more important than that from Shift 3. The framework is not a rigid prescription; it adapts by shifting the weight among the three components based on the type of change.
What I'm Doing
I started building StructPR because of this problem.

Max's talk crystallized what I had been observing for years: the way we present code changes to reviewers is structurally broken, and alphabetical file listing is a design choice we inherited from the earliest diff tools, not one anyone deliberately chose. Nobody sat down and decided that alphabetical was the best way to review code. It was the default, and defaults persist long after the reasoning behind them disappears.
StructPR is a GitHub app that reorganizes pull request reviews by business impact and change type instead of alphabetical file listing. It automatically groups changed files into three to seven logical clusters — "Authentication," "Payment Processing," "Database Migrations," "Tests" —so the reviewer sees the story of the change before reading individual diffs. It shows execution flow: how a request moves through the changed files, from routes to controllers to database changes. The grouping is pattern-based and deterministic; consistent results in under two seconds. No AI involved in the grouping itself; just structural analysis of what changed and how those changes relate to each other.
This addresses Shift 1 directly. It does not solve Shift 2 or Shift 3; those require process changes and cultural decisions that no tool can make for you. I believe the presentation problem is the most overlooked of the three shifts because it is invisible---we've been looking at alphabetical file lists for so long that we stopped noticing the cognitive cost.
I might be wrong about the implementation. The product is new; the bet might not pay off. But the underlying problem is measurable, the research supports it, and the bottleneck is widening every quarter as AI generates more code and review capacity stays flat. Building something felt more honest than writing about it and doing nothing.
Questions Worth Asking for your team
How long does it take a PR to go from "ready for review" to merged in your organization? Has that number changed since your team started using AI coding tools?
What percentage of your review comments are about things a linter could catch? If you don't know, that number is worth measuring.
When your reviewers open a PR, do they understand the business intent of the change before reading the first line of code? Or are they reconstructing that intent from an alphabetical file list?
If AI tools are generating 47% more PRs for your team, who is absorbing that review load? And what are they not doing while they review?
Do your reviewers see the story of change — what it does, why it matters, and how it flows through the system? Or do they see an alphabetical list of filenames and reconstruct the story themselves?
The bottleneck in software was never typing speed. AI proved that by eliminating it. The bottleneck is understanding---understanding what changed, why it changed, and whether it should have changed at all. Code review is where understanding lives or dies. The question is whether your review process is built for that job or is still optimized for the one it used to do.